
Comment diviser par 2 la tailles d’un model Fine-tune en local afin d’économiser du stackage sans que cela enlève de la qualité d’image lors de génération. Passer d’un model fp16 à fp8.
Je tiens à présenter mes sources.
- Chaine Youtube : SeCourses
- Vidéo en question (à 49mn38) : FLUX Full Fine-Tuning / DreamBooth Training Master Tutorial for Windows, RunPod & Massed Compute
- Patreon de SeCourses : https://www.patreon.com/c/secourses/home
Outils :
- windows
- Kohya
Ouvrir Kohya
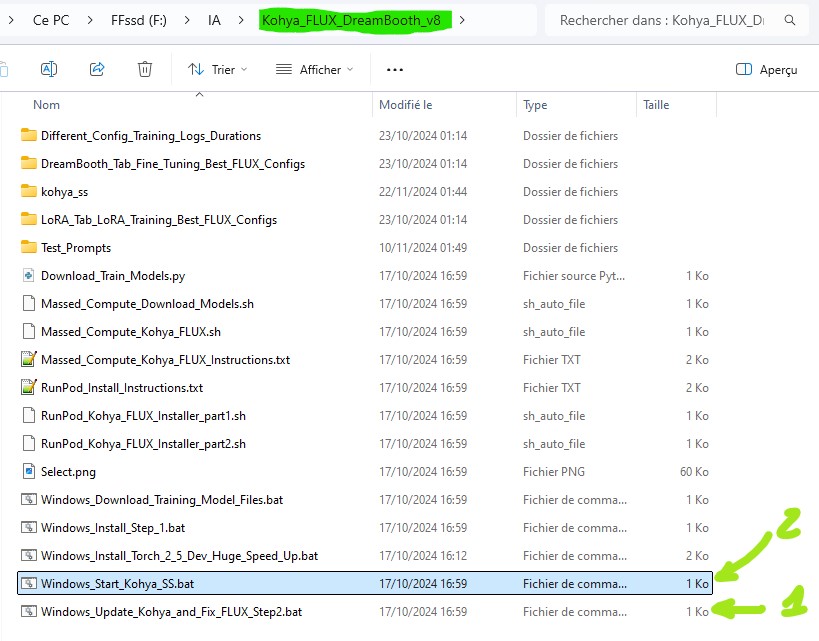
- mettre à jour Kohya
- lancer Kohya
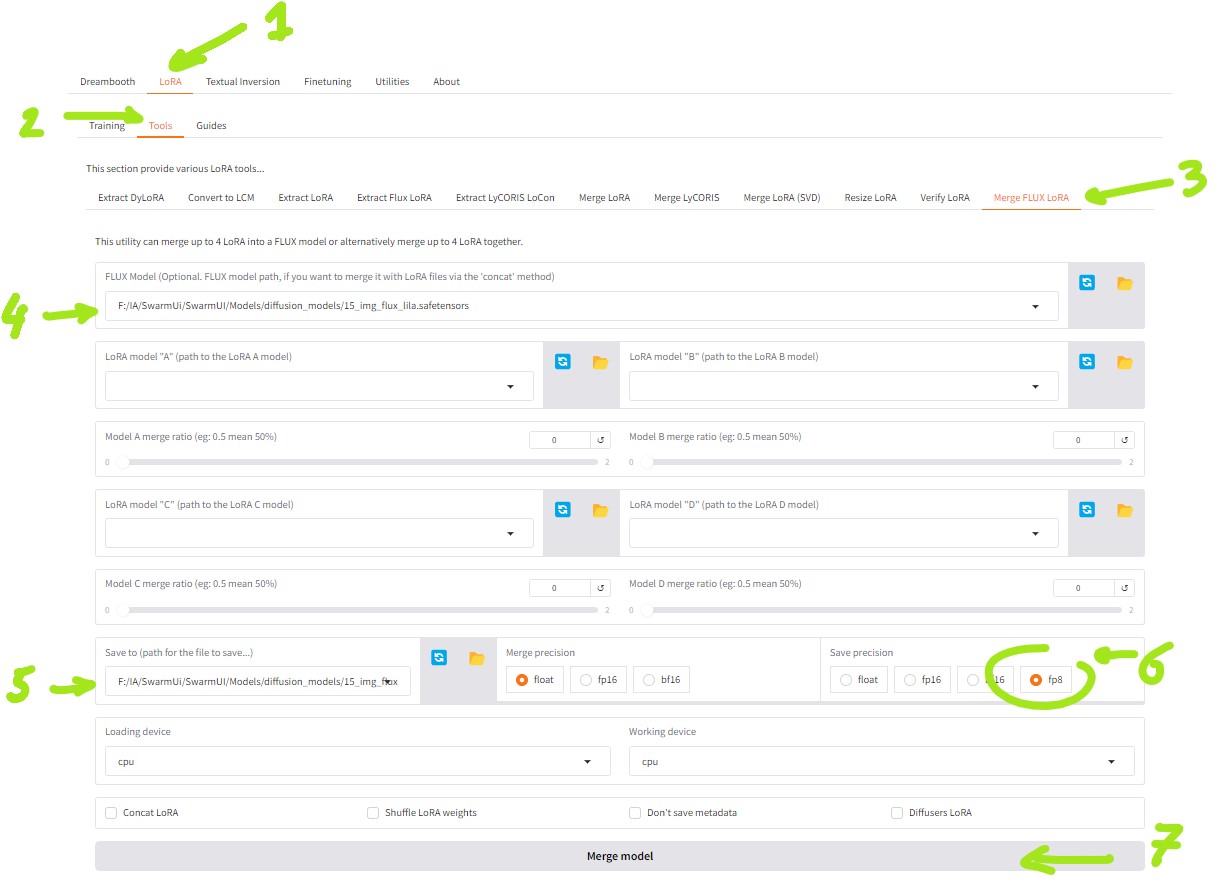
Configurer Kohya pour redimensionner :
- Aller dans Lora
- Tools
- Merge Flux Lora (cela marche de la même manière pour les model Lora que pour les model entier.)
- renseigner le chemin et le model à redimensionner
- renseigner le même chemin et model en y ajoutant ‘_fp8’ pour le différencier.
- selectionner la case fp8
- et lancer en cliquant sur ‘merge model’
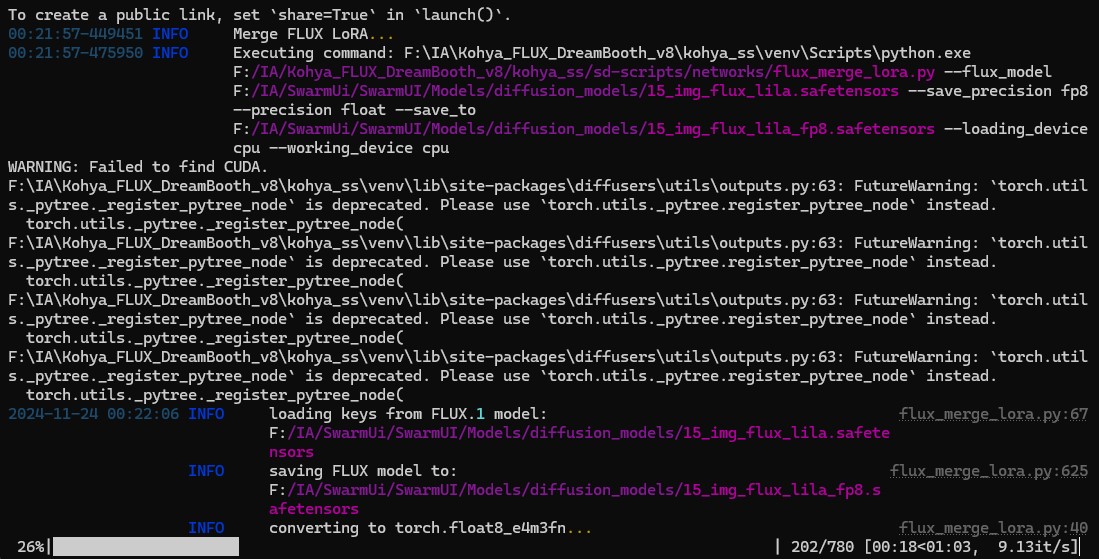
Progression du redimensionnement :
Cela dure avec ma configuration 1mn55. Il faut compter (en ce qui me concerne) bien 1 minute de plus pour la copie du fichier de la RAM au disque Dur.

Résultat :
